Road To PPO. Part I

Using a state-of-the-art implementation
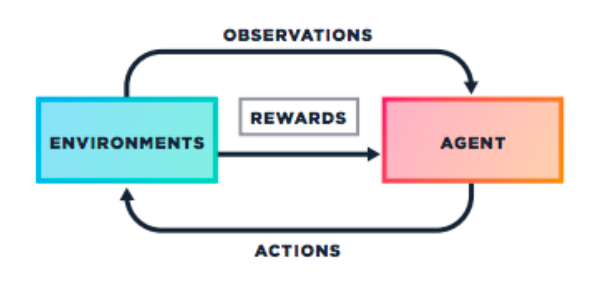
Reinforcement Learning is a subfield of machine learning providing a very exciting theory. Its principle is to have an agent, ie. a program interact with a world and optimize its behaviour to maximize a reward. To me, one of the most interesting things in this formulation is that this method requires no model, hence is called model-free.
However, beyond a very sexy theory, Reinforcement Learning runs into a lot of practical problems, like explained here, here and here. Which means that, in my cases, trials were systematically met with failure. Also, I realized that a huge amounts of tips and tricks were needed to train sucessfully an agent, and some of these tips are not always clearly documented. But to be fair, while it is (extra) though for us, simple mortals, some people obtained results great enough to make one’s eyes sparkle while contempling the possibilities yielded by these accomplishments.
The PPO algorithm was introduced in 2017 and I’ve spent a lot of time fighting with it to get it working. It’s main strength is to prevent the policy from straying too much from an older version of it, which in theory prevents it from falling into local minimas and not being able to come out of it. I needed this algorithm to work both for PhD reasons and also be able to train my own agents to face me in my Unity games. Finally, after a long time failing at it, I decided to start using the OpenAI implementation that would, I hoped, allow me to gain some insights and move things forward while I figure out the secrets of this method.
Setup
These implementations are designed to work with the gym framework, so the first step was to transform my custom environment following gym guidelines and principles.
To do so you need to:
- Make sure your environment inherits from
gym.Env - Uses the
gym.Spaceclass for encapsulating both the observation space and the action space - Provide some meta informations about it.
After that, simply create a package of your environment like explained here
Enjoy the magic
Add video