Road To PPO. Part II

Curating a famous implementation to a simpler one
Last time, I left off I was happy with my new working agent. However I can’t shake the guilty feeling of using something that I don’t completely master. I don’t think it is possible to have control over everything one interacts with, and I suppose there’s nothing wrong about it. But still, for various reasons, such as being able to modify on will the agent, have more flexibility, I wanted to work more on the PPO implementation.
Objectives
In order to come up with my own, tailored, suitable and working implementation, I decided to follow a specific plan:
- Switch the OpenAI implementation relying on Tensorflow to a PyTorch one. So far, the best I’ve found is Ilya Kostriskov’s
- Given that these implementations are rather general, because designed to work seamlessly with all of gym, RoboSchool, MuJoCo environments and various algorithms, strip it to the bare minimum.
- Once the lite version is working, construct an equivalent version with my own means.
- Scale it up.
Step 1: Getting acquainted with Ilya’s work
Ilya Kostriskov’s implementation is really great. It worked out of the box and the agent quickly reached the maximal reward in my custom environement. Annoyingly, the script relies on Visdom for visualizing the reward history. This I plan to change to another plotting library. While stripping the code, I realized that:
- The implementations borrows heavily to OpenAI’s baselines.
- In particular, most of the multiprocessing part. This is for parallelizing the environements and having the agent interacting with various versions of it, hence multiplying experiences. Also, I suppose it helps avoiding the agent getting stuck, modifying badly the policy and failing completely. Some kind of early reset.
- Highly important: The whole VecNormalize process and Monitor that scales the rewards, the observations. This is fundamental. The agent is most likely to fail without it
- It is really important to initialize the policy and the critic with small weights (I had actually figured this out while working on GANs)
- The rest follows mostly what one can understand reading the paper.
Step 2: Let’s go minimal
My first impulse was to rebuild most of the code. I started from a empty file and progressively worked my way through the main.py file, adding modules, functions and others sweets when I judged they were necessary for the lite version. Given the devil’s in the details, I obviously missed some elements with led me to a marathon trying to find where were hiding the bugs. I finally reached a running script… which was nothing but good at training agents.
Gaving up this method I started again from the opposite direction. Using the full code, I progressively removed the unwanted elements and reached my goal. The full code can be found here. It is a set of scripts destined to run a PPO agent in a continuous environment with low-level perceptions (ie. no images)

Step 3: Switching Visdom for TensorBoard
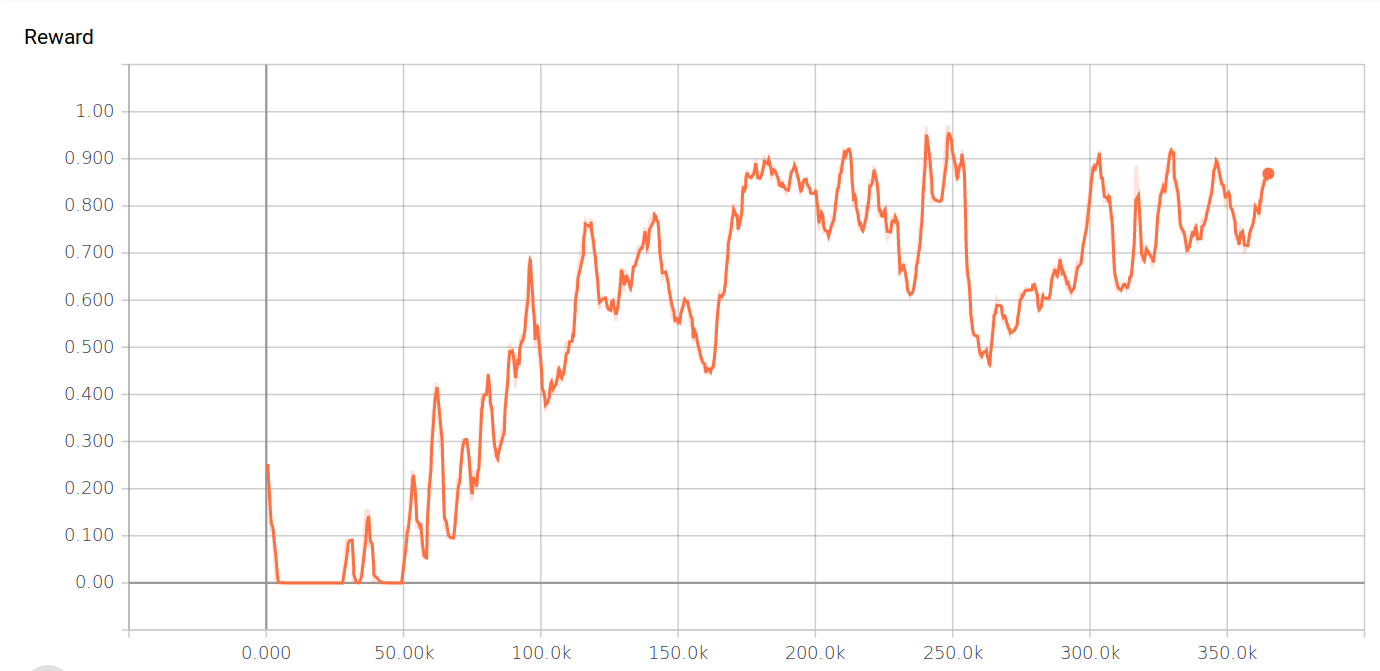
I’m not really a fan of Visdom. The animal kept sending me error messages about not mixing floats and None types, though I couldn’t find any mention of this in my code. Also, this issue has already been submitted to the relevant github repo. Also, I enjoy TensorBoard smoothness. So, I got rid of Visdom. My current implementation calls a SummaryWriter, from tensorboardX and registers all the rewards values. Which finally give a much nicer visualisation, in my humble opinion.